
I spent a weekend benchmarking GitHub's hidden AI security reviewer. The cheapest model held its own.
What 200 reviews across five frontier LLMs told me about cost, variance, and whether you should trust a single run.

There's an undocumented/experimental command inside GitHub Copilot CLI called /security-review. I stumbled across it while setting up Copilot on my work account, looked for an announcement, found nothing, and got curious.
The idea is straightforward: you finish a coding session, the command reads your diff, and it hands back a list of likely vulnerabilities. The kind of thing you'd want running on every PR, in theory. But there's a question the manual experience can't answer. How much does the underlying model actually matter?
Does paying for Opus over Haiku buy you better security findings? Or are you just paying more for the same answer in a fancier wrapper? And (this is the one that nagged at me) can you trust a single run, or is one scan just a noisy slice of what the model "really" thinks?
So I spent a weekend building a small harness to find out. What follows is what came out of it. Some of it was very interesting to me.
A weekend, a vulnerable app, and 200 reviews
Here's the setup, briefly.
I needed something with a known answer key, and OWASP Juice Shop is the obvious pick: a deliberately vulnerable Node.js app that ships with a catalogued list of known issues. I took the original app and created 10 changes, each one reintroducing one or more catalogued vulnerabilities. 14 vulnerabilities total across the 10 changes, spanning the usual OWASP territory: SQL injection, weak crypto, SSRF, path traversal, XXE, insecure deserialization, broken access control, hardcoded credentials, missing rate limiting, open redirect.
The ground truth (which file, which CWE, a one-line explanation) lives in a catalogue.md. The AI reviewer never sees this file. That part matters.
For each change, I run /security-review non-interactively and capture the output. (Quick note for anyone trying to do this themselves: the --no-ask-user flag is critical. Without it the command pauses for user input after its first pass and never terminates in a script. With it, you get a clean JSON stream and a final result event that tells you exactly how many credits the run consumed.)
Then a separate, fixed LLM grader takes the catalogue and the reviewer's output and produces three counts per change: detected, missed, false positives. The grader sees the catalogue. The reviewer doesn't. The grading model stays constant across all runs so any grader bias is a constant offset across models. I went big on the grader and used Opus 4.6.
I ran this across 5 models × 4 independent runs × 10 changes = 200 reviews. It's a small sample, but tokens are expensive and I was funding this out of curiosity, not a budget. Enough to see the broad shape, not enough to publish in a journal.
The models, for the record: Claude Haiku 4.5, Sonnet 4.6, Opus 4.6, GPT-5.4, GPT-5.5. These are all the ones currently selectable for Copilot CLI.
What came out
Mean detection rate across 4 runs, with range and standard deviation:
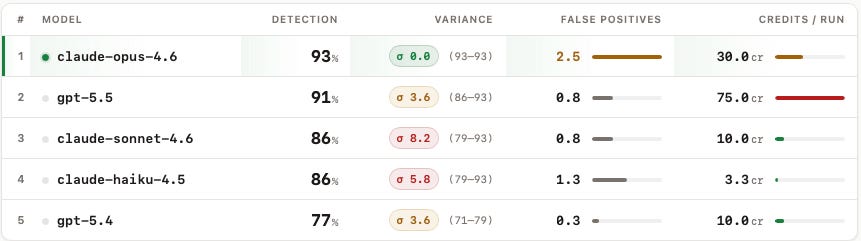
Two things in that table stopped me when I first ran the numbers.
1. Haiku 4.5 tied Sonnet 4.6 on mean detection, at about a third of the cost.
Both landed at 86% mean detection. Haiku costs 3.3 credits per 10-change sweep. Sonnet costs 10. That's a 3× spread for the same outcome on this benchmark.
If you're planning to run /security-review on every PR in a busy repo, this is the line item to look at first. Sonnet does have slightly fewer false positives on average (0.8 vs 1.2), so it's not strictly dominated, but it's close enough that it changed how I think about the workflow. Instead of "pick the best model for security review," it became "pick the cheapest competent model, then optionally use a bigger one to triage what it finds."
The interesting question isn't which model is best. It's which model is good enough to throw at every PR, and which one do you reserve for the diffs that matter.
2. Opus was the only model with zero variance across runs.
Opus scored 13/14 every single time. Same detection rate, same missed vulnerability, four runs in a row. Robotic.
Everything else moved. Sonnet ranged from 79% to 93% across its four runs. Haiku did the same. That's a 14-percentage-point swing for "the same model on the same input." That number was a bit surprising when I first saw it, so I went back and double-checked the runs. Looking back, given the non-determinism of LLMs, they're correct and should be expected.
If your security gate is a single /security-review run, and the model behind it is mid-tier, you are partly looking at noise. This was the finding that genuinely changed my mind. Re-running matters more than I'd assumed before doing this. And it raises a practical question: could running a cheap model twice and combining the findings be roughly as good as running a frontier model once, while still being cheaper? I haven't tested it. It's the most interesting follow-up this benchmark surfaced.
The cost question
Credits are bucketed per model. Every Haiku run cost exactly 3.3, every Opus run exactly 30.0, and so on. So the table below isn't anecdotal cost data. It's the actual price list as observed in 200 reviews.
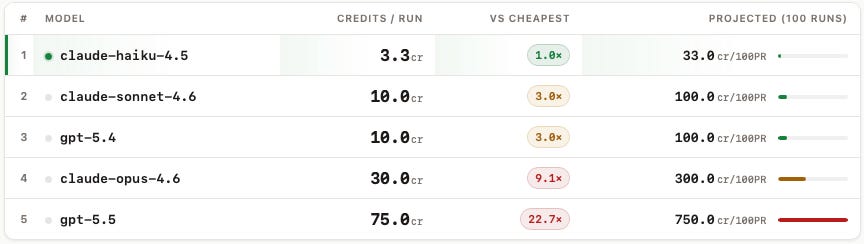
Let's translate that into something more concrete. A team running /security-review on 100 changes per week with Haiku spends about 330 credits/week on security review. The same workload on GPT-5.5 spends 7,500.
That's not a small difference, and it's the thing I keep coming back to: is this kind of analysis even worth the tokens it consumes with the frontier models?
At the Haiku end the cost-benefit case writes itself. The numbers are tiny and the detection rate is competitive. At the GPT-5.5 end you're paying 22× more for one percentage point less detection than Opus. That's harder to defend, especially in organisations that already have other security tooling in place.
My take, after staring at this for longer than is reasonable: probably yes for high-stakes diffs (auth changes, crypto, anything touching session handling), and no for the long tail. The frustrating thing is that the tool doesn't help you make that call right now. You pick a model and it runs everywhere.
So at minimum: pick the model with intention. Don't take the default.
A long list of caveats, because this is a side project and not deep research
I'd rather make a smaller true claim than a bigger shaky one, so let me be honest about what this benchmark isn't.
n=4 is small. The "Haiku ties Sonnet" finding is consistent with these runs but it isn't statistically established. With higher run counts the gap might widen, narrow, or invert. I'm not going to spend all my company's tokens on this. I do need some left to get the AI to do my actual job.
Juice Shop is well-known. It almost certainly appears in training data for all five models, which would inflate scores roughly uniformly across them. That's why the interesting comparisons here are *between* models, not the absolute detection rates. There are better benchmarks out there. I was playing around with something small, so I picked something familiar.
The grader sees the catalogue. It's calibrated to "does this finding match a catalogued vuln," which isn't a perfect 1:1 match and the AI grader can be wrong. I spot-checked a sample of matches and they were correct, so I trust the grader is roughly right, but I haven't done a formal evaluation for every single finding.
One workload. This is /security-review against Node.js diffs with common OWASP-class bugs. It tells you nothing about Rust unsafe blocks, business-logic flaws, supply-chain attacks, or anything in a less popular language. My hunch is that less common languages would show bigger gaps between the frontier and mid-tier models, but it's a hunch.
Models change. This snapshot is from late May 2026. If you're reading this six months from now, pricing and capabilities have probably shifted enough to change the ranking.
What I'd do next if I were funding this properly
A short shopping list, if I ever pick this up again with a real budget:
- Push n to 10+ per model and settle the Haiku-vs-Sonnet question for real.
- Add a private repo benchmark alongside Juice Shop to neutralise training-data effects.
- Test "2× Haiku with union of findings" head-to-head against "1× Opus". That's the most useful practical question this whole exercise raised and it's still wide open.
- Add a second independent grader to calibrate inter-rater reliability, or replace the AI grader with something more deterministic where possible.
So, should you actually use /security-review?
If you've made it this far, that's the question on your mind. My honest answer:
Yes, but be deliberate about the model. The default isn't obviously right. Haiku is shockingly competitive. Opus is the only model whose single-run result you can trust without re-running. GPT-5.5 is hard to justify at 22× the cheapest option for one percentage point of detection.
If you've played with /security-review and seen different patterns, or if you have ideas for codebases that would make better benchmark targets, I'd like to hear about it. The most interesting findings in this space are going to come from people running this on private code and reporting back.
Quick answers to the questions I know are coming
Did the grader have access to the catalogue? Yes. The grader gets the catalogue as ground truth and is asked whether each scorecard finding matches a catalogued vuln. The reviewer does not see the catalogue, only the diff. The grading model is fixed across all runs so any grader bias is constant.
Why Juice Shop? Isn't it too well-known? That's the trade-off. Public means it likely leaks into training data, which inflates scores roughly uniformly across models. But it gives me a high-quality answer key, which is hard to manufacture. A private corpus would be more rigorous but I couldn't have shared the harness.
n=4 is not a benchmark. Agreed. It's enough to surface that single-run results are noisy (σ of 5–8pp for two models) and that the cost/quality ranking has interesting overlap. It is not enough to rank models with confidence.
Why not include Gemini / DeepSeek / Llama? Limited by what /security-review exposes in Copilot CLI for me.
Originally written up on dev.to. This is the longer, more reflective version.